¿Qué es overfitting?
El overfitting (sobreajuste) ocurre cuando una red neuronal (o cualquier modelo de IA) aprende demasiado bien los datos de entrenamiento, hasta el punto de memorizar sus detalles y errores, en lugar de aprender patrones generales.
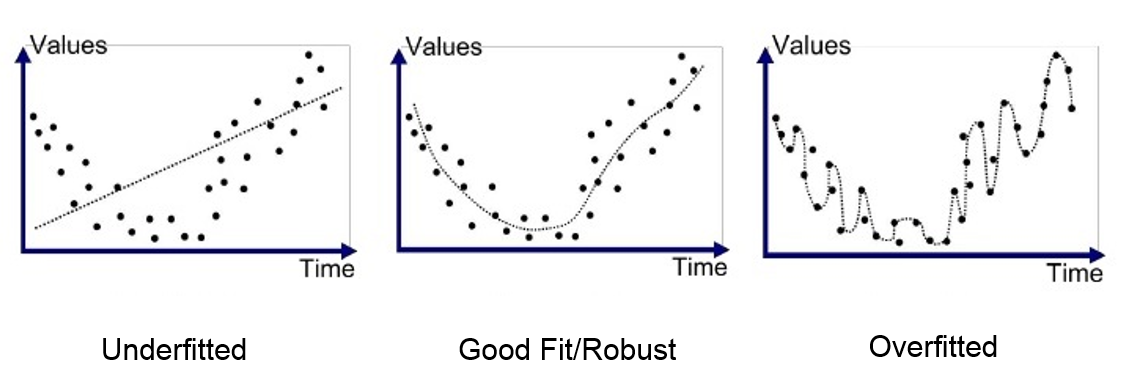
🔍 Ejemplo intuitivo
Imagina que enseñas a un niño a reconocer perros:
Si le muestras solo tus fotos de tu perro, aprenderá a reconocer a TU perro, pero fallará con otros.
Eso es overfitting: el niño (el modelo) se adaptó demasiado a ejemplos específicos y no generaliza.
📉 Síntomas de overfitting
Alta precisión en entrenamiento, pero baja precisión en validación/test.
La red se vuelve muy compleja: muchos parámetros ajustados a detalles irrelevantes.
El error de validación empieza a subir mientras el error de entrenamiento sigue bajando.
⚠️ Causas principales
Pocos datos de entrenamiento.
Modelo demasiado complejo (muchas capas, demasiados parámetros).
Entrenamiento demasiado largo sin control.
Datos ruidosos o desbalanceados.
🛠️ Cómo evitarlo
Más datos o data augmentation.
Regularización (L1, L2).
Dropout (apagar neuronas al azar).
Early stopping (detener cuando la validación empeora).
Modelos más simples (no siempre “más grande” es mejor).
Cross-validation para comprobar que generaliza.
¿En qué puedo ayudarte?
Deja una respuesta