¿Qué es el algoritmo K-means?
El algoritmo k-means es un método de aprendizaje no supervisado utilizado en clustering (agrupamiento). Su objetivo es dividir un conjunto de datos en k grupos (clusters) diferentes, de forma que los elementos dentro de un mismo grupo sean lo más parecidos posible entre sí y lo más diferentes posible de los de otros grupos.
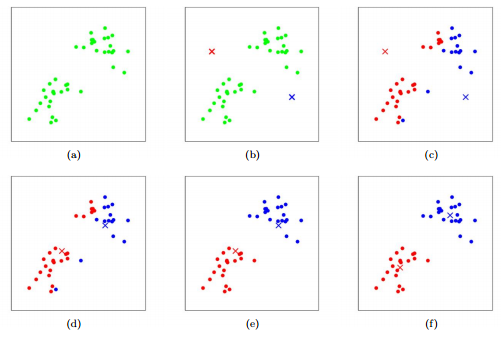
Funcionamiento básico:
Elegir el número de clusters (k) que quieres formar.
Inicialización: se seleccionan aleatoriamente k puntos como centros iniciales de los clusters (llamados centroides).
Asignación: cada dato se asigna al cluster cuyo centroide esté más cerca (normalmente se usa la distancia euclídea).
Recalcular centroides: se calcula el nuevo centroide de cada cluster como el promedio de todos los puntos asignados a él.
Iterar: se repiten los pasos 3 y 4 hasta que los centroides no cambien significativamente o se alcance un número máximo de iteraciones.
Ejemplo intuitivo:
Imagina que tienes un conjunto de puntos en un plano que representan clientes con dos características: ingresos y edad. El algoritmo k-means puede agruparlos, por ejemplo, en 3 clusters:
Clientes jóvenes con ingresos bajos.
Clientes de edad media con ingresos medios.
Clientes mayores con ingresos altos.
Ventajas:
Es rápido y sencillo de implementar.
Escala bien con conjuntos de datos grandes.
Limitaciones:
Hay que fijar el número de clusters (k) antes de ejecutar.
No siempre encuentra la mejor solución global, a veces se queda en un óptimo local.
Funciona peor si los clusters no son esféricos o tienen tamaños muy diferentes.
¿En qué puedo ayudarte?
Deja una respuesta